Tablo ASCII y su historia: Descubre cómo este código binario de caracteres revolucionó la computación. Conoce sus 128 caracteres, desde letras y números hasta símbolos de control. Explora el ASCII extendido y su evolución hacia Unicode para abarcar más idiomas. Aprende cómo el ASCII sigue siendo relevante en software y HTML, incluso en la actualidad.
ASCII, es una tabla de caracteres para computadoras. Es un código binario utilizado por equipos electrónicos para manejar texto usando el alfabeto inglés, números y otros símbolos comunes.
ASCII es una abreviatura de American Standard Code for Information Interchange. ASCII se desarrolló en la década de 1960 y se basó en códigos anteriores utilizados por los sistemas telegráficos.
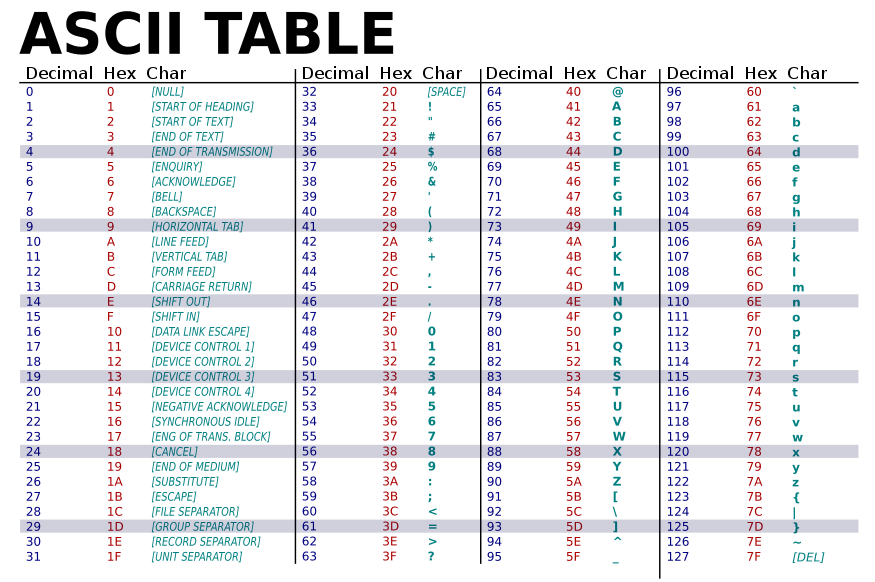
El código incluye definiciones para 128 caracteres: la mayoría de estos son los caracteres imprimibles del alfabeto, como abc, ABC, 123 y? & !. También hay caracteres de control que no se pueden imprimir, sino que controlan cómo se procesa el texto, por ejemplo, para comenzar una nueva línea. Esos están en la columna izquierda de la tabla a continuación. La mayoría de los personajes de control ya no se usan para su propósito original. No hay control de formato real (para negrita o cursiva, etc.)
A veces alguien habla de un archivo o documento en ASCII, lo que significa que está en texto plano.
ASCII usa 8 dígitos binarios (bits) para representar caracteres: 1000001 (o 41 en hexadecimal o 65 en números estándar de base 10) representa la letra mayúscula A; 1000010 representa B; 1000011 representa C; y así sucesivamente en secuencia. Ocho bits permitieron incluir un bit de paridad en cada byte enviado a través de un puerto serie o módems, este bit se utiliza para evitar errores. Esto fue más importante hace años cuando las conexiones a menudo eran ruidosas.
ASCII extendido
ASCII no tiene signos diacríticos (marcas que se agregan a una letra, como los puntos (diéresis) sobre las vocales en alemán, o la tilde (~) sobre la ‘n’ para la ‘ñ’ utilizada en español). Solo estaba destinado al inglés y no funciona bien para la mayoría de los otros idiomas. Algunas palabras en inglés tomadas de otros idiomas también usan estas marcas, como currículum (ver Apéndice: palabras en inglés con signos diacríticos).
Esto llevó a que algunos sistemas usaran 8 bits (un byte completo) en lugar de 7 bits. El nombre apropiado para los sistemas que usan 8 bits se llama ASCII extendido. Ocho bits permiten 256 caracteres. Los primeros 128 caracteres deben ser los mismos que para ASCII y el resto generalmente se usa para letras alfabéticas con acentos, por ejemplo, como É, È, Î y Ü. Esto resuelve el problema para los idiomas que se basan en el alfabeto latino, aunque no todos los sistemas ASCII extendidos son iguales. Otros alfabetos, como el alfabeto griego, el alfabeto cirílico, necesitan un conjunto diferente de caracteres. Y algunos sistemas como los que usan caracteres chinos todavía no funcionan, ya que usan miles de caracteres. Entonces, Unicode fue creado para tener un sistema común para todos los idiomas.
El ASCII estándar todavía se usa comúnmente, particularmente en software de computadora y archivos HTML. Hasta 2010 era el estándar para las URL. A menudo, un sitio web que tiene campos para ingresar texto solo tomará texto ASCII. Cualquier marcado especial para texto en negrita o centrado, etc. se mostrará incorrectamente.



